Transactional Replication and Stored Procedure Execution: Silver Bullet or Poison Pill?

Transactional Replication, by design, is prone to latency. It’s not a synchronous operation, like with database mirroring. The published database will happily continue to churn through transactions while the log reader scrambles to record data changes to send to the distribution database. Once the log reader has collected all the changes, it ships them off to the distributor, who then has the unfortunate job of actually storing and delivering the changes to the replicas. That’s at least 3 points of latency right there:
- How fast can the log reader agent read your log files to scan for n changes?
- How fast can the log reader deliver and write the transactions to the distributor?
- How fast can the distribution agent enact each change at your subscriber(s).
Of all the points listed above, it’s usually number 3 where we start to get into trouble. And that’s because of how transactional replication delivers transactions. There are ways to alter that behavior, but before we go any further, it’s worth looking at why that’s the way it is.
When a daddy transaction and a mommy transaction love each other very much…
With replication, the transaction you run at the publisher isn’t what you get the subscriber. We saw that in my last post about monitoring replication latency with extended events. To refresh your memory, let’s say I have AdventureWorks2014 published for replication. If I run an update statement that updates one row, I get 1 transaction in my distribution database to match:
UPDATE [AdventureWorks2014].[Person].[EmailAddress] SET EmailAddress = 'drewfurgiuele@adventure-works.com', ModifiedDate = GETDATE() WHERE BusinessEntityID = 1 and EmailAddressID = 1
We can query the distribution database and find our transaction by first looking at the dbo.MSrepl_transactions table. It should have a date and time that correspond to our transaction:
-- list all recent transactions logged by replication SELECT * FROM dbo.MSrepl_transactions
![]()
Once we have the transaction sequence number (xact_seqno) we can query dbo.MSrepl_commands to find each transaction that was part of it:
-- get a list of commands for a given transaction SELECT * FROM dbo.MSrepl_commands where xact_seqno = 0x00000032000001600049
![]()
So there we go: one transaction with one command = one row in the transactions table in distribution, and one matching command for the transaction. If we run an update that changes, say, ~20,000 rows it puts the same ~20,00 changes in distribution and we’ll see a new transaction row added, and roughly 20,000 commands that correspond (19,972 to be exact):
UPDATE [AdventureWorks2014].[Person].[EmailAddress] SET ModifiedDate = GETDATE()
For brevity, here’s the same two queries above and their results:
-- hey replication, what'cha doin? SELECT * FROM dbo.MSrepl_transactions -- cool story bro, tell me more about this transaction (0x00000036000006A000AE) SELECT * FROM dbo.MSrepl_commands where xact_seqno = 0x00000036000006A000AE
![]()
If that wasn’t enough, each one of those 20,000 transactions has to be delivered, one at a time, to the subscriber. We can see this by using extended events to monitor it:
![]()
Why you gotta do a thing?
Some people might be wondering why replication does things this way. After all, isn’t this just another type of cursor? Aren’t cursors supposed to be bad? The main reason it does this is for transactional consistency. After all, if this is truly a “replica” of your data, you’d expect 20,000 updated rows on your publisher to update 20,000 rows on your subscriber, right? By applying one transaction at a time, replication is also being “helpful” in that if there’s a row it CAN’T update (or delete, or insert due to a duplicate key), it’s going to fail, throw an error, and then roll back entire batch of transactions.
So in a way, delivering one at a time is kind of a safety net of sorts, but it comes at a cost. Not only does it have to deliver each transaction one at a time, while your subscriber is processing the changes from the distribution agent, any other changes are being read on the subscriber, and then written to distribution, waiting for this batch of transactions to finish applying so it can do the next series. Think of it as when there’s a big accident on a big freeway and 4 lanes of traffic suddenly go down to 1; all the cars behind it have to merge down to one lane which causes everything to slow down.
One trick to managing latency is to split out your publications to multiple publications so if you have a table the gets large, batch updates you can isolate it to it’s own publication, and other tables can live in a separate one. That way, transactions can process in parallel. This isn’t a perfect solution either, since now you just have double the agents, and double the activity, on your distribution database. We’ll see more about that in a different blog post.
An alternative?
There is a way to get replication to process in batches instead of one at a time, and that’s with published stored procedures. In a published database, you can do more than replicate just tables: you can replicate views, functions, and even stored procedures. However, just publishing them just gets the schema of the object on the subscriber. You can set the option for execution of the procedure in the article properties at the publisher.
One good example of how this can benefit you are back-fills of new columns. Typically, you’d add a new column to a table, then fill it with some data. Maybe the data is static, or maybe there is logic to whether or not it gets a certain value. To keep things simple, let’s say I want to add a column to the Person.Person table called [DoNotSolicit] and set it to a bit value of 1 or 0. Here’s the code:
ALTER TABLE [AdventureWorks2014].[Person].[Person] ADD [DoNotSolicit] bit GO UPDATE [AdventureWorks2014].[Person].[Person] SET [DoNotSolicit] = 0 GO
If we run the same queries we used in the previous section, we’d see two new transactions in our database, each with a series of commands. Interestingly, the ALTER TABLE command generates multiple commands as a DDL statement, but the data update just generates 19,972 commands (since we’re updating every row in the table). Those transactions have to be read by the log reader, stored in the distribution database, and then delivered, one at a time, to the subscriber.
Let’s write a stored procedure to do something similar:
CREATE PROCEDURE [dbo].[backfill_DoNotSolicit]
(
@newValue bit
)
AS
BEGIN
UPDATE [Person].[Person] SET [DoNotSolicit] = @newValue
END
Once the stored procedure exists at the publisher, let’s mark it for replication:
![]()
In the box above, we first select our stored procedure to replicate, then we use the article properties dialog box to tell the procedure to replicate the execution of the stored procedure as well. With this box checked, when we execute our stored procedure, instead of individual transactions being read, stored in the distribution database, and then delivered to the subscribers, we only get one statement, pretty much everywhere. Once we run the snapshot agent to get the stored procedure sent to the replica, let’s go ahead and run our procedure:
EXECUTE [dbo].[backfill_DoNotSolicit] 1
![]()
Here’s distribution, with only one command in the transaction (the outlined row is the transaction that contains the command in question):
![]()
And here’s the only statement replicated at the publisher:
![]()
In the above picture, we can see that it did replicate the execute statement, and that it affected 19,972 rows on the replica, and it only took 67ms! Sounds awesome, doesn’t it? Here’s a way to handle large batch updates at your publishers without overwhelming your replication setup. But before you go changing everything, you should probably understand that this has some really, really bad side effects if you’re not careful. Let’s look at three really big ones.
Gotcha #1: What if all the objects don’t exist?
Let’s modify our stored procedure a bit, and introduce some advanced logic for our do not solicit customers:
ALTER PROCEDURE [dbo].[backfill_DoNotSolicit]
(
@postalcode nvarchar(15),
@DoNotSolicitFlag bit
)
AS
BEGIN
UPDATE p
SET p.DoNotSolicit = @DoNotSolicitFlag
FROM Person.Person p
INNER JOIN Person.BusinessEntity be ON be.BusinessEntityID = p.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID = be.BusinessEntityID
INNER JOIN Person.Address a ON a.AddressID = bea.AddressID
WHERE a.PostalCode = @postalcode
END
One thing worth mentioning: just like other DDL statements, once a stored procedure is published for replication, modifying it on your published database will send the changes to your subscriber(s).
In a nutshell let’s say we want this stored procedure to set a do not solicit flag for people who live in a certain zip code, so we join over the Person.Address table. In my topology, I’m only replicating Person.Person , not the other tables in the query. I’ll run the alter statement, and then run an update for a postal code:
![]()
It affects 20 rows at my publisher, and I get one transaction and one command in replication. At my subscriber though, well, things aren’t going well at all:
![]()
Why is the same stored procedure showing up as running more than once in our extended event at our subscriber? Eventually, replication monitor will show us why:
![]()
The stored procedure is choking at my subscriber because the other tables in my procedure code don’t exist, and since replication LOVES to be helpful, it’s going to retry this command till it works, or it tries to do it 2,147,483,647 times. Then it’ll quit trying. To fix this if this happens to you, you have two options:
- Delete the offending transaction from distribution. Find the command in question, and delete that row from distribution. You can use the same queries above to find the offending transaction and smite it, but this requires you modifying system-level data (technically), “which seats it in the crazy, not stupid, section.”
- Replicate the tables that are missing.
Gotcha #2: Three part names
This one is technically the same as above, but if you write code that does cross-database calls, and those database don’t exist at your subscribers, you’re going to run into the same issue. If you weren’t comfortable deleting the offending transactions out of distribution before, you might as was cozy up to it now, because unless you want to replicate an entirely other database to your subscriber, you’re better off removing the transaction from distribution and snapshotting your tables over to get what you need.
Gotcha #3: Subscription data concurrency
While gotchas #1 and #2 are annoying but avoidable, gotcha #3 is the real risk here. Before I show you how this is a real problem for this replication technique though, we need to look at my current example topology:

I have two diagrams here. The first diagram, in blue, is the simplest topology for replication. It represents one publisher, with one publication that contains all the articles. It delivers to one subscriber database. In this set up, transactions are processed in the order they are received. This is easy and nice from a concurrency standpoint, but this has some limitations. First, if you have a large transaction with many commands, things can pile up behind it, and you’re left with transactions waiting to deliver. A single publication for a large database can also be tough manage, too, in the case of snapshots or changes.
The second diagram, in orange, is a little different. Here, we have one published database, but we have multiple publications for the database all pointing to a subscriber database. You can see which articles I’m replicating in each publication. This set up is more flexible; if we have tables that are busy with changes we can split them into different publications to increase throughput; a table that has a large batch of commands won’t slow down the tables in the second publication. You still only have one log reader in this example, but transactions can come and go for multiple publications at the same time. The downside to this type of set up is that your distribution database usage increases a lot, so you need to account for the extra agents and workload.
In the case of the orange layout with traditional replication command delivery, concurrency isn’t too much of an issue, because each command will be delivered individually and by primary key values. For example, running an update like this:
UPDATE Person.Address SET PostalCode = '43017' WHERE AddressID = 18710 GO UPDATE p SET p.DoNotSolicit = 1 FROM Person.Person p INNER JOIN Person.BusinessEntity be ON be.BusinessEntityID = p.BusinessEntityID INNER JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID = be.BusinessEntityID INNER JOIN Person.Address a ON a.AddressID = bea.AddressID WHERE a.PostalCode = '98312' GO
Will still maintain concurrency with the publisher, even if the second transaction is delivered and applied at the subscriber first. That’s because each transaction will be applied with the primary key of the row receiving the update; nothing should be missed, even if things are delayed.
With stored procedure replication, though, this gets… complicated. Let’s keep with the example stored procedure I have above, but now I have my topology configured like my orange diagram. We’re going to set the do not solicit flag on a bunch of people based on zip code again. But this time, we’re going to execute 4 batches of commands:
UPDATE Person.Person SET DoNotSolicit = 0 UPDATE Person.EmailAddress SET ModifiedDate = GetDate() GO UPDATE Person.Address SET PostalCode = '43017' WHERE AddressID = 18710 GO EXECUTE dbo.backfill_DoNotSolicit 98312, 1 GO
In this scenario, let’s assume that our company needs to reset our “do not solicit” data for our database. We’re first going to set everyone’s flag to 0. Then we’re going to generate some “dummy” load for replication by setting everyone’s modify date on the email address table to “now.” I’m including this step for a reason, even though it doesn’t really pertain to the changes we’re trying to make (more on that in a minute). Then, before I run my stored procedure that will update the do not solicit flag for an entire zip code, my data quality team tells me that there’s one person who has a wrong zip code in the table. Well, we don’t want to mark them incorrectly, so we better change that before the procedure, right? Then, we run the the procedure to set the flag for zip code 98312.
Before we run our update at the publisher though, let’s make things interesting. At our subscriber, we’re going to introduce some latency to our subscribers. I’m going to run the following query:
BEGIN TRANSACTION SELECT * FROM Person.EmailAddress WITH (HOLDLOCK) WHERE EmailAddress LIKE '%Adventure%'
This will place an exclusive lock on the Person.EmailAddress table, which means our updates for email address will wait on a lock to be released before they can apply. Leaving that transaction open for now, we’ll go back to our publisher, and after executing the transactions we can see the results of our queries:
![]()
And when I query my Person.Address table for the DoNotSolicit bit column on my publisher, I get 181 results:
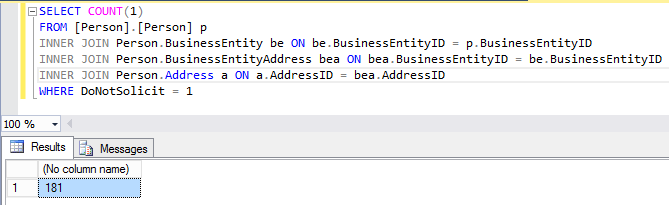
But at our subscriber:
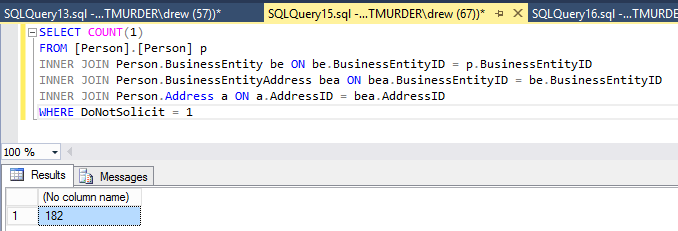
So what happened? Because we had a HOLDLOCK on our table in our example (which we did on purpose for demo purposes here), the updates for EmailAddress and Address were held up and couldn’t be applied until the lock was released on our subscriber. However, the stored procedure execution is in a separate publication, so that transaction was delivered after the other transactions, but executed before the other transactions (including our zip code update) completed.
Our extended event session confirms this:

We see that the stored procedure was executed before our email address updates, which happens before our postal code update. Again, this happens because:
- We have some sort of delay (intentional or otherwise!) in transactions being delivered in a publication that contains objects that are used by our published stored procedure,
- Our stored procedure execution, which was executed after those updates, is delivered separately in a different publication. It executes, updates rows based on code logic, not primary keys (like normal transactional replication),
- Our other updates deliver as normal once the delay or latency clears up.
And now you’re in a tough spot because your data is out of sync with productions. While this doesn’t break SQL Server in any way, if you have people writing reports that the business relies on against this replica, well, you’ll be channeling your inner Gob.
But should you use it?
Clearly, this replication feature has some advantages. It keeps your distribution database tidy, it facilitates set-based transactions at your replicas, and it eases pressure on your log reader, too. If you implement it well, it can save you a lot of time and headaches for recurring data processes that slow down your replication. The trade-offs here though are substantial, especially the part that might make it so your replicas have incorrect data. And I’m not comfortable with that, so typically don’t use this feature.
If you are considering using it, I suggest the following:
- Any stored procedures you replicate the execution for that update more than one table should live in the same publications as those tables. If you have tables that are part of different publications apart from the stored procedures, you could encounter the concurrency problem shown above. If they are, then the execution of the procedures will follow any updates to those tables and be executed serially after any updates to them.
- Be mindful of your referenced objects. Are all the tables used by the stored procedure present? What about cross database calls?
For me, I don’t normally replicate stored procedures at all; not the code, not the execution of them. However, if the business has a requirement to update lots of rows of data and I can plan ahead for it, I might consider taking their code, creating a stored procedure to process the changes, and then publish it. And when I’m finished, I’ll remove the stored procedure from replication and drop it from my replica(s). That way, I can be mindful of the issues, and conduct validation when I finish, that everything worked the way I wanted it to, and clean up after myself afterwards.
Pingback: Transactional Replication Procedures – Curated SQL
Another potential problem: what if the stored procedures have logic based on the current date. Won’t they be executed on the subscriber at a different time and thereby have different behavior?
Absolutely right!